- easy-rl PDF版本 笔记整理 P3
- joyrl 比对 补充 P4 - P5
- 相关 代码 整理 ——> 有空 另开一页
最新版PDF下载
地址:https://github.com/datawhalechina/easy-rl/releases
国内地址(推荐国内读者使用):
链接: https://pan.baidu.com/s/1isqQnpVRWbb3yh83Vs0kbw 提取码: us6a
easy-rl 在线版本链接 (用于 copy 代码)
参考链接 2:https://datawhalechina.github.io/joyrl-book/
其它:
【勘误记录 链接】
——————
5、深度强化学习基础 ⭐️
开源内容:https://linklearner.com/learn/summary/11
——————————
表格型:蒙特卡洛、Q-learning、Sarsa
状态转移概率 p [ s t + 1 , r t ∣ s t , a t ] p[s_{t+1},r_t|s_t,a_t] p[st+1,rt∣st,at]: 在状态 s t s_t st 选择动作 a t a_t at 后, 转移到状态 s t + 1 s_{t+1} st+1,得到奖励 r t r_t rt 的概率。
马尔可夫性质: 系统下一时刻的状态仅由当前时刻的状态决定, 不依赖于以往任何状态。
状态转移概率 和 奖励未知: model-free。 免模型
模型未知 或 模型太大 ——> 免模型方法
考虑未来的总奖励的原因: 奖励延迟
折扣因子 γ \gamma γ: 当前行为 对 太远的未来的某一个回报可能毫无关系。
用下一状态的价值 来更新 当前状态的 价值。 自举
时序差分: 每走一步更新一次 Q 表格, 用下一个状态的 Q 值 来 更新当前状态 的 Q 值。
蒙特卡洛方法:
采样大量 episode ,计算所有 episode 的真实回报,计算平均值, 当做 状态值的估计。
蒙特卡洛:
V
(
s
t
)
←
V
(
s
t
)
+
α
(
G
i
,
t
−
V
(
s
t
)
)
V(s_t)\leftarrow V(s_t) +\alpha(G_{i,t}-V(s_t))
V(st)←V(st)+α(Gi,t−V(st))
时序差分:
V
(
s
t
)
←
V
(
s
t
)
+
α
(
r
t
+
1
+
γ
V
(
s
t
+
1
)
−
V
(
s
t
)
)
V(s_t)\leftarrow V(s_t) +\alpha(r_{t+1}+\gamma V(s_{t+1})-V(s_t))
V(st)←V(st)+α(rt+1+γV(st+1)−V(st))
| 时序差分 | 蒙特卡洛 |
|---|---|
| 可在线学习,效率高 | 必须等游戏结束 |
| 不要求序列完整 | 完整序列 |
| 连续任务 | 有终止的任务 |
| 马尔可夫 | 非马尔可夫更高效 |
| 有偏估计 | 无偏估计 |
| 方差小、自举 | 方差大 |
时序差分 优势: 低方差, 能够在线学习, 能够从不完整的序列中学习。
————————————————
证明:对于任意 策略 π \pi π, 根据其动作价值函数 q π q_\pi qπ 计算的 ε \varepsilon ε -贪心策略 π ′ \pi^\prime π′ 比原策略 π \pi π 好 或 至少一样好。
π ( a ∣ s ) = { ε ∣ A ( s ) ∣ + 1 − ε , 贪心动作 ε ∣ A ( s ) ∣ , 其它动作 \pi(a|s)=\left\{ \begin{aligned} &\frac{\varepsilon}{|\mathcal{A}(s)|}+1- \varepsilon, &贪心动作\\ &\frac{\varepsilon}{|\mathcal{A}(s)|}, &其它动作\\ \end{aligned} \right. π(a∣s)=⎩ ⎨ ⎧∣A(s)∣ε+1−ε,∣A(s)∣ε,贪心动作其它动作
由上式:
——>
π
(
a
∣
s
)
−
ε
∣
A
(
s
)
∣
=
{
1
−
ε
,
贪心动作
0
,
其它动作
\pi(a|s)-\frac{\varepsilon}{|\mathcal{A}(s)|}=\left\{ \begin{aligned} &1- \varepsilon, &贪心动作\\ &0, &其它动作\\ \end{aligned} \right.
π(a∣s)−∣A(s)∣ε={1−ε,0,贪心动作其它动作
——>
π
(
a
∣
s
)
−
ε
∣
A
(
s
)
∣
1
−
ε
=
{
1
,
贪心动作
0
,
其它动作
\frac{ \pi(a|s)-\frac{\varepsilon}{|\mathcal{A}(s)|}}{1-\varepsilon}=\left\{ \begin{aligned} &1, &贪心动作\\ &0, &其它动作\\ \end{aligned} \right.
1−επ(a∣s)−∣A(s)∣ε={1,0,贪心动作其它动作
q π ( s , π ′ ( s ) ) = ∑ a ∈ A π ′ ( a ∣ s ) q π ′ ( s , a ) = ε ∣ A ( s ) ∣ ∑ a ∈ A q π ( s , a ) + ( 1 − ε ) max a ∈ A q π ( s , a ) = ε ∣ A ( s ) ∣ ∑ a ∈ A q π ( s , a ) + ( 1 − ε ) ∑ a ∈ A π ( a ∣ s ) − ε ∣ A ( s ) ∣ 1 − ε max a ∈ A q π ( s , a ) ≥ ε ∣ A ( s ) ∣ ∑ a ∈ A q π ( s , a ) + ( 1 − ε ) ∑ a ∈ A π ( a ∣ s ) − ε ∣ A ( s ) ∣ 1 − ε q π ( s , a ) 这个 q π ( s , a ) 没有 ε 贪心动作对应的 q 大 = ∑ a ∈ A π ( a ∣ s ) q π ( s , a ) \begin{aligned}q_\pi(s, \pi^\prime(s))&=\sum\limits_{a\in\mathcal A}\pi^\prime(a|s)q_{\pi^\prime}(s,a)\\ &=\frac{\varepsilon}{|\mathcal{A}(s)|}\sum\limits_{a\in\mathcal A}q_\pi(s, a)+(1-\varepsilon)\max\limits_{a\in\mathcal A}q_\pi(s, a)\\ &=\frac{\varepsilon}{|\mathcal{A}(s)|}\sum\limits_{a\in\mathcal A}q_\pi(s, a)+(1-\varepsilon)\textcolor{blue}{\sum\limits_{a\in \cal A}\frac{ \pi(a|s)-\frac{\varepsilon}{|\mathcal{A}(s)|}}{1-\varepsilon}}\max\limits_{a\in\mathcal A}q_\pi(s, a)\\ &\geq \frac{\varepsilon}{|\mathcal{A}(s)|}\sum\limits_{a\in\mathcal A}q_\pi(s, a)+(1-\varepsilon)\sum\limits_{a\in \cal A}\frac{ \pi(a|s)-\frac{\varepsilon}{|\mathcal{A}(s)|}}{1-\varepsilon}q_\pi(s, a)~~~\textcolor{blue}{这个 ~q_\pi(s, a) ~没有~ \varepsilon ~贪心动作 对应的 ~q ~ 大}\\ &=\sum\limits_{a\in\mathcal A}\pi (a|s)q_ \pi (s,a)\end{aligned} qπ(s,π′(s))=a∈A∑π′(a∣s)qπ′(s,a)=∣A(s)∣εa∈A∑qπ(s,a)+(1−ε)a∈Amaxqπ(s,a)=∣A(s)∣εa∈A∑qπ(s,a)+(1−ε)a∈A∑1−επ(a∣s)−∣A(s)∣εa∈Amaxqπ(s,a)≥∣A(s)∣εa∈A∑qπ(s,a)+(1−ε)a∈A∑1−επ(a∣s)−∣A(s)∣εqπ(s,a) 这个 qπ(s,a) 没有 ε 贪心动作对应的 q 大=a∈A∑π(a∣s)qπ(s,a)
————————————
偏差高: 偏离真实数据
方差高: 数据分布分散。
时序差分: 更新 V
Sarsa:更新 Q
q
(
s
t
,
a
t
)
=
q
(
s
t
,
a
t
)
+
α
[
r
t
+
1
+
γ
q
(
s
t
+
1
,
a
t
+
1
)
⏞
时序差分目标
−
q
(
s
t
,
a
t
)
⏟
时序差分误差
]
q(s_t, a_t)=q(s_t,a_t)+\textcolor{blue}{\alpha}[\underbrace{\overbrace{\textcolor{blue}{r_{t+1}+\gamma q(s_{t+1},a_{t+1})}}^{时序差分目标}-q(s_t,a_t)}_{时序差分误差}]
q(st,at)=q(st,at)+α[时序差分误差
rt+1+γq(st+1,at+1)
时序差分目标−q(st,at)]
Sarsa: ( s t , a t , r t + 1 , s t + 1 , a t + 1 ) (\textcolor{blue}{s}_t, \textcolor{blue}{a}_t,\textcolor{blue}{r}_{t+1}, \textcolor{blue}{s}_{t+1}, \textcolor{blue}{a}_{t+1}) (st,at,rt+1,st+1,at+1)
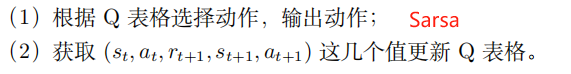
Sarsa: 同策略的时序差分
Q-learning: 异策略的时序差分
q ( s t , a t ) = q ( s t , a t ) + α [ r t + 1 + γ max a q ( s t + 1 , a ) ⏞ 时序差分目标 − q ( s t , a t ) ⏟ 时序差分误差 ] q(s_t, a_t)=q(s_t,a_t)+\alpha[\underbrace{\overbrace{r_{t+1}+\gamma \textcolor{blue}{\max_{a}q(s_{t+1},a)}}^{时序差分目标}-q(s_t,a_t)}_{时序差分误差}] q(st,at)=q(st,at)+α[时序差分误差 rt+1+γamaxq(st+1,a) 时序差分目标−q(st,at)]
同策略:学习的策略 和 与环境交互的策略 是同一个。不稳定、胆小。 Sarsa
异策略:目标策略 和 行为策略。 激进。 Q-learning
————————
Q 表格: 横轴 动作, 纵轴 状态
同策略 VS 异策略: 生成样本的策略 和 参数更新的策略 是否相同。
Q 学习, 异策略, 优化策略 没有用到 行为策略的数据。
时序差分 使用了 自举, 实现了 基于平滑的效果, 方差较小。
——————————————
joyrl
免模型:
不需要学习较为复杂的模型 (状态转移概率 和 奖励)
需要与真实环境进行大量的交互。
异策略算法:从经验池或者历史数据中进行学习的。
其一是智能体在测试的时候直接用模型预测的动作输出就行,即在训练中是采样动作(带探索),测试中就是预测动作,其二是训练过程中不需要更新策略,因为已经收敛了。